About my project#
Abstract#
Recent studies have suggested that the Vision Transformer (ViT) architecture could potentially outperform Convolutional Neural Network (CNN) in solving complex game environments. However, the full potential of ViT in replacing CNN has yet to be realised. This research project aims to explore the efficacy of the Swin Transformer, a recently introduced ViT model, as the primary network backbone in the Double Deep Q Network (Double DQN) algorithm. The objective is to determine if ViT can achieve results that are as good as or better than those achieved by CNN.
During the course of my research, I came across a paper titled “Deep Reinforcement Learning with Swin Transformer” by Meng et al. (2022), which had already implemented Swin Transformer and conducted a comparison with CNN. I attempted to replicate their experimentation to determine if I could achieve similar results. However, my findings were different from theirs.
My results indicate that CNN outperforms Swin Transformer, especially with a smaller number of training steps. CNN also requires less computing power and memory compared to Swin Transformer, which necessitates more data and a recent GPU with sufficient VRAM. To achieve better results than CNN, Swin Transformer may require a higher number of training steps, as demonstrated by Meng et al. (2022).
You can also check the code on GitLab:
Introduction#
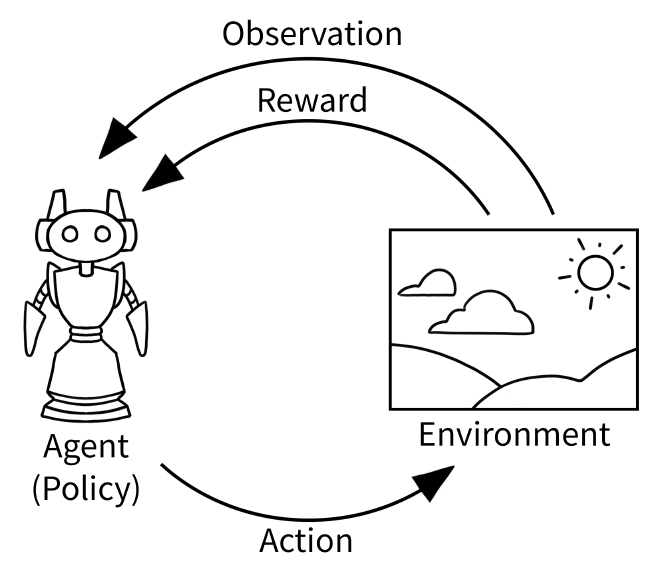
Deep Reinforcement Learning is a subfield of machine learning that combines the principles of reinforcement learning and deep learning. When applied to video games, Deep RL represents a promising alternative to traditional AI algorithms because it enables the agent to learn and act in its environment without any prior knowledge or interference from a human player.
An agent can use various algorithms, supported by a neural network, to learn. This neural network processes the input the agent “sees”, passing through hidden layers before reaching the output layers. The best action is selected from the output layer, and the agent continues to progress through the environment.
Convolutional Neural Networks are still the go-to neural networks used in a variety of image-recognition tasks. The goal of this project is to see if Vision Transformer, which is a recent architecture, can perform better in the same kind of tasks, and in this case, in the field of Deep Reinforcement Learning.
The present research aims to provide a fresh perspective on the usage of Convolutional Neural Networks and their modern alternative, Vision Transformers, in video game environments. The central research question that guides this investigation is: “What advantages does using a Vision Transformer model offer over CNN in playing video games?” To delve deeper into this research question, three sub-questions have been formulated, namely:
- How effective are CNNs in addressing computer vision challenges in video games?
- Which Vision Transformer architecture would be most effective in addressing computer vision problems in video games?
- What challenges are associated with training a neural network agent using Vision Transformers compared to CNNs?
To ensure a fair comparison of the neural networks, precise criteria must be used consistently throughout the experiments. This research also includes tables and graphics displaying the data collected through the research.
CNN and ViT are tested and compared on the Atari games Pong and Breakout. The conclusions drawn from this research provide information on the two neural networks and their suitability for different video game contexts. This will help video game developers choose the most appropriate neural network model for their needs.
Technologies#
To ensure a fair and unbiased comparison, state-of-the-art software libraries and frameworks were used for this project. All tools utilised were open source and widely recognised in the research community.
Frameworks and Libraries#
Python was chosen as the primary programming language for this project due to its widespread use in the machine learning community and the wealth of technical resources available in Python.
I exclusively use open-source libraries and frameworks. Although not exhaustive, the following list comprises the principal and most critical libraries used in my work.
| Technology | Version | Description |
|---|---|---|
| PyTorch | 2.0 | Machine Learning framework for deep neural networks developed by the Linux Foundation umbrella. |
| Gymnasium | 0.28.1 | Standard API for reinforcement learning, and a diverse collection of reference environments. |
| Stable-Baselines3 | 1.8.0 | Set of reliable implementations of reinforcement learning algorithms in PyTorch. |
| Jupyter Notebook | 6.5.4 | Interactive web-based Python code interface. |
| Transformers | 4.28.1 | State-of-the-art collection of Transformers neural network architectures developed by Hugging Face. |
Development Tools#
- Linux – Ubuntu-based Operating System (i.e. Pop!_OS or Ubuntu) version 22.04
- Miniconda: small bootstrapped version of Anaconda. Anaconda is an open-source package and environment management system that improves the default Python environment management and pip package manager.
- JetBrains PyCharm Professional: my favourite multipurpose Python IDE
- Git: version control system to manage code
Experiments#
The present study sought to replicate the approach of Meng et al. (2022), which entailed employing the Double DQN algorithm in conjunction with a Convolutional Neural Network, and subsequently replacing the CNN with a Swin Transformer. For each experiment, identical algorithmic and hyperparameter settings were employed.
I ran experiments on two Atari games, Breakout, and Pong. These experiments aimed to measure the effectiveness of the two neural networks at solving the game environments, with a focus on their ability to learn and improve their performance over time.
I measured the performance of each neural network by tracking the average reward and maximum score achieved during gameplay over time. The results of these experiments are analysed and presented in the next section. The input to both the CNN and Swin Transformer networks is a stack of four grayscale frames reduced to a size of 84×84.
Double Deep Q Network#
The Double Deep Q Network algorithm is the core component of the experiment. The exact hyperparameters used in the algorithm are described below.
| Input | 4x84x84 |
| Optimiser | Adam |
| Adam learning rate | 0.0001 |
| Loss function | Smooth L1 |
| Max timesteps | 10,000,000 |
| Target update interval | 1,000 |
| Learning starts | 100,000 |
| Train frequency | 4 |
| Replay buffer size | 10,000 |
| Batch size | 32 |
| Discount rate (gamma) | 0.99 |
| Exploration fraction | 0.1 |
| Final exploration rate (epsilon) | 0.01 |
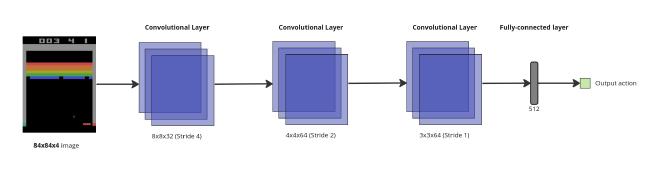
Convolutional Neural Network#
| Layers | 3 |
|---|---|
| Blocks each layer | 2, 3, 2 |
| Heads each layer | 3, 3, 6 |
| Patch size | 3x3 |
| Window size | 7x7 |
| Embedding dimension | 96 |
| MLP ratio | 4 |
| Drop path rate | 0.1 |
Swin Transformer#
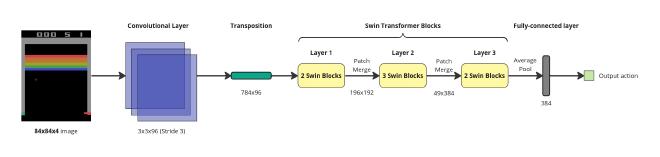
For the Swin Transformer architecture, the complexity of the model makes finding good parameters challenging. The architecture used in this project was adapted from Meng et al. (2022) and includes three layers of Swin Blocks, each containing 2, 3, and 2 blocks and 3, 3, and 6 attention heads, respectively. The patch size is set to 3×3, which yields 28×28 patches given the input size of 84×84 for the four channels. The embedding dimension for each patch is 96, resulting in a token size of 784×96 after patch embedding. The local window size is 7×7 and the windows are shifted by 3 patches for the first and third blocks. The MLP ratio is 4, indicating that the linear layers within Swin Blocks have 4 times the embedding dimension hidden units, i.e., 384. The drop path rate is set to 0.1, indicating a 10% chance that the input is kept as it is in skip connections (Meng et al. 2022).
| Layers | 3 |
|---|---|
| Filters per layer | 32, 64, 64 |
| Strides per layer | 4, 2, 1 |
| Kernel size per layer | 8, 4, 3 |
| MLP Units | 64x7x7 = 512 |
Results#
This section presents the findings of my research, in which an agent was trained on Pong and Breakout environments using the Double Deep Q-Network with both CNN and Swin Transformer architectures. For a more detailed explanation of the results, please refer to my thesis, as the content on this webpage has been kept concise.
Pong#
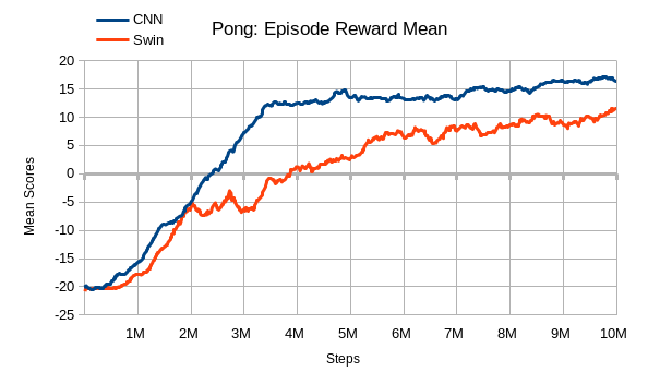
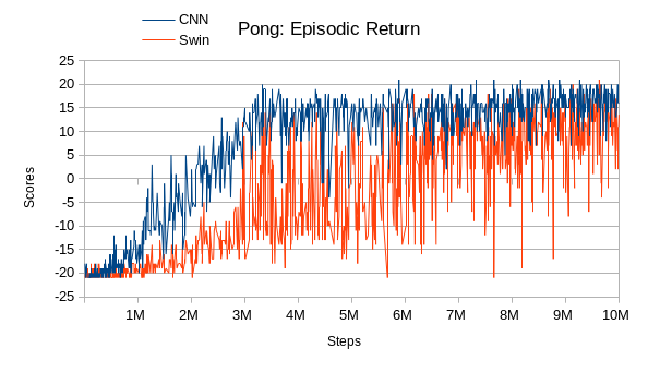
The CNN agent achieved good performance and required a relatively short training time of 7 hours and 36 minutes on a GTX 970 GPU. It began to converge around 500,000 steps, with a stable increase until it reached 3.5 million steps, where it stabilized. However, it did not achieve a mean reward of +/- 20.
The Swin Transformer-based DQN agent required a substantially longer training period of 3 days and 7 hours on an RTX 3080 GPU. It only began to score positively at around 4 million steps, but showed a constant increase in performance compared to the CNN model. However, it was not able to achieve the same mean reward as the CNN model, achieving only around ~12. Its performance curve was less linear, exhibiting consistent drops to lower scores for a certain period before increasing again.
Also, an interesting comparison can be made between CNN and Swin, by observing the agents playing directly. The agent trained with CNN took actions in an erratic manner, whereas the Swin Transformer appeared to be smoother, despite its lower mean reward. This behavior is critical in video games since the smoother it is, the more appealing it will be to a human player. This behaviour can be seen in the video below and gives the impression that the Swin DQN agent thinks more before taking an action than the CNN agent (the agent is the right paddle, left paddle is a dummy computer AI).
Breakout#
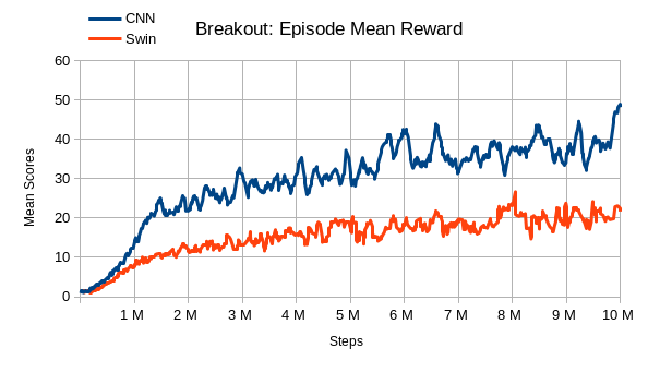
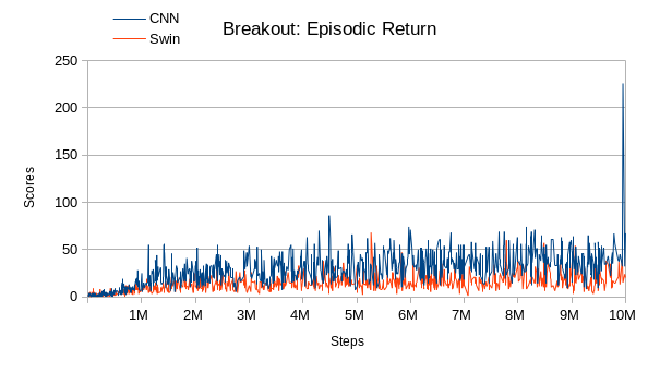
The CNN agent was trained for 1 day and 7 hours on an NVIDIA GTX 970 GPU, while the Swin agent required a significantly longer training period of 3 days and 6 hours on an NVIDIA RTX 3080 GPU. Interestingly, the Swin Breakout agent required less time to train than the Swin Pong agent, while the CNN Breakout agent required more time than the CNN Pong agent, despite being trained on the same hardware and under the same conditions. The reasons for these results are not immediately clear and may be due to random factors rather than the neural networks themselves.
In terms of performance, the CNN agent outperformed the Swin agent in Breakout, achieving a mean reward of almost 50 and a better episodic return overhaul, while the Swin DQN agent occasionally performed better for a few episodes. Overall, the Swin agent’s performance was worse than Pong, with a mean reward that was more than double that of the CNN agent. The convergence point for both agents started early in training, before 1 million steps. These results suggest that Breakout requires more than 10 million steps for proper training, although the CNN agent was able to achieve better results in less time.
Compared to Meng et al. (2022), my results on Breakout show lower scores for the first 10 million steps. This difference may be due to random factors or the choice of seed. In their paper, Swin DQN and CNN DQN achieved relatively similar results, which became sparser closer to 2 million steps. This suggests that the Swin agent requires more time and data to achieve optimal performance compared to the CNN agent.
Conclusion#
The primary objective of this project was to compare the performance of a Vision Transformer variant with its CNN counterpart using the Deep Q Network (DQN) algorithm, a widely recognised Reinforcement Learning (RL) algorithm. However, during the research phase, a paper titled “Deep Reinforcement Learning with Swin Transformer” (Meng et al.2022) was encountered, which had already replaced the CNN with the Swin Transformer model. Despite this, the idea of replicating their work and comparing my results with theirs remained intriguing, especially given my limited knowledge of hyperparameter tuning if I were to try a completely different architecture.
The conclusion of the Meng et al. paper showed that the Swin DQN outperformed its CNN counterpart. However, my results indicated that the CNN outperformed the Swin DQN in the two tested games, Pong and Breakout. Despite this, the results were still significant and interesting compared to the paper, indicating that the Swin Transformer’s computational complexity and time requirements for training an agent are higher than those of the CNN. The higher results obtained by Meng et al. (2022) demonstrate that the Swin Transformer requires a significantly higher number of training steps.
Training an agent with Swin Transformer is computationally intensive and requires significant GPU memory, making it challenging for an average computer and not feasible for consumer video games due to the low number of individuals who own such hardware. Therefore, the CNN remains a viable option for high-performance algorithms, considering the hardware of the end-user machine.
Despite this, the Swin Transformer offers certain advantages over the CNN that are not related to raw performance. A fascinating comparison can be made between the CNN and Swin by observing the agents playing directly. The agent trained with CNN took actions in an erratic manner, whereas the Swin Transformer appeared to be smoother, despite its lower mean reward. This behavior is critical in video games since the smoother it is, the more appealing it will be to a human player.